
AI・機械学習
創造する人と、加速するAIをつなぐ
高性能GPUを活用した計算環境と開発基盤をまとめて整備・提供し、すぐに使える環境をご用意します
AI技術とは

AI技術とは、コンピューターが人間の知的活動(学習、理解、推論、問題解決、創造、意思決定など)を模倣・支援する技術の総称です。
AIの真価を支える中核技術の1つが 機械学習(Machine Learning)で、特に 深層学習(Deep Learning)の登場により、 自然言語処理、 画像認識、音声認識などの分野で成果が飛躍的に向上しました。 生成AIは、この学習成果をもとに、文章や画像、音声などを人間らしい形式で自動生成する技術であり、近年は研究や産業の双方で活用が急速に広がっています。
これらの技術は数十年にわたる理論研究と実践の蓄積の上に成り立っており、今後も新しい学習手法や応用領域の拡大によって業務への統合や、より高度で実用的な活用が期待されています。
AI技術を支える計算環境

AI・機械学習の研究・開発では膨大なデータを高速処理するための GPUを中心とした計算基盤が不可欠です。 深層学習モデルの大規模化に伴い高速演算ユニット、大容量VRAM、多数の並列処理コアといった性能に加え、安定した電源供給や冷却設計、最適化された開発環境(例: CUDA / ROCm )など、ハードウェアと基盤構築の両面で高い品質が求められます。
弊社では、これらの要求に応えるためGPUサーバーを中心としたハードウェア構成に加え、開発基盤のセットアップから基本的な動作確認までをまとめて提供しています。GPU以外のアクセラレーターやCPU主体の環境でも、すぐに開発を始められるベース環境をご用意可能です。用途や規模に応じて柔軟にカスタマイズできますので、ぜひご相談ください。
性能要件
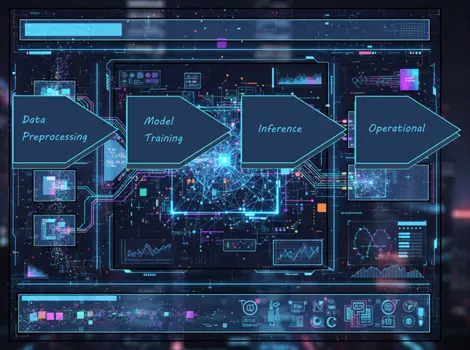
AI処理は、「 データ前処理」「 モデル学習(トレーニング)および検証(バリデーション)」「 推論(インファレンス)」「 運用(MLOps)」と段階によって求められるリソースが異なります。 大規模モデルの学習では、GPUの並列演算性能や VRAM容量が成果に直結し、複数GPUを使う場合には電源や冷却設計の安定性も欠かせません。
一方で小~中規模の学習やデータ前処理ではCPU性能やメモリ容量、ストレージ速度が処理効率を左右します。 推論ではリアルタイムで処理する性能が重要で、GPUの容量や処理速度に加え開発環境での安定動作も求められます。こうした段階ごとの要件を踏まえ、最適なハードウェア構成を選ぶことが学習から運用までのワークフローを効率化するうえで重要です。
AI処理のフェーズ
機械学習モデルが効率的に学習できるように、生のデータを準備するプロセスです。現実世界のデータはノイズが多く、欠損値を含み、形式も不均一なことが多いため、そのままではモデルに適用できません。
および検証(バリデーション)
準備されたデータを用いて、モデルが特定のタスクを遂行できるように学習(トレーニング)を行い、その過程で精度を評価するための検証(バリデーション)を実施します。 モデルは、データ内に含まれるパターンや関係性の学習と検証を繰り返すことで、未知のデータに対しても予測や分類を行える能力を獲得します。
学習済みのモデルを使い、未知の新しいデータに対して予測や判断を行うプロセスです。モデルの学習が完了し、本番環境にデプロイされた後に実行されます。
機械学習モデルを本番環境で継続的に実行・管理し、ビジネス価値を提供し続けるための一連のプラクティスです。「MLOps(Machine Learning Operations)」は、開発(Dev)と運用(Ops)を統合するDevOpsの概念を機械学習に適用したものです。
| データ前処理 | モデル学習(トレーニング)および検証(バリデーション) | 推論(インファレンス) | 運用(MLOps) |
|---|---|---|---|
| 機械学習モデルが効率的に学習できるように、生のデータを準備するプロセスです。現実世界のデータはノイズが多く、欠損値を含み、形式も不均一なことが多いため、そのままではモデルに適用できません。 | 準備されたデータを用いて、モデルが特定のタスクを遂行できるように学習(トレーニング)を行い、その過程で精度を評価するための検証(バリデーション)を実施します。 モデルは、データ内に含まれるパターンや関係性の学習と検証を繰り返すことで、未知のデータに対しても予測や分類を行える能力を獲得します。 | 学習済みのモデルを使い、未知の新しいデータに対して予測や判断を行うプロセスです。モデルの学習が完了し、本番環境にデプロイされた後に実行されます。 | 機械学習モデルを本番環境で継続的に実行・管理し、ビジネス価値を提供し続けるための一連のプラクティスです。「MLOps(Machine Learning Operations)」は、開発(Dev)と運用(Ops)を統合するDevOpsの概念を機械学習に適用したものです。 |
主な作業
|
主な作業
|
主な作業
|
主な作業
|
処理内容別ハードウェア推奨構成
pandas、scikit-learnなど軽量分析向け
| CPUコア数 | 8~16コア |
|---|---|
| メモリ | 32~64GB |
| VRAM | 任意 |
| ストレージ | SSD推奨 |
PyTorch、TensorFlowなどモデル学習向け
| CPUコア数 | 8~16コア |
|---|---|
| メモリ | 64~128GB |
| VRAM | 8~16GB以上 |
| ストレージ | NVMe SSD |
Hugging Face、vLLMなど大規模学習向け
| CPUコア数 | 16~32コア |
|---|---|
| メモリ | 128GB以上 |
| VRAM | 40GB以上 |
| ストレージ | SSD/NVMe RAID構成 |
| 高速インターコネクト | NVLink、Infiniband、100G/200G Ethernet |
リアルタイム推論やバッチ処理によってGPU/メモリ要求が変動。PyTorch、TensorFlow、ONNX Runtimeなど
| CPUコア数 | 8~16コア |
|---|---|
| メモリ | 32~64GB |
| VRAM | 8~24GB |
| ストレージ | NVMe SSD |
MLOps向けツール例:Kubeflow、MLflow、Weights & Biases
| CPUコア数 | 32~64コア |
|---|---|
| メモリ | 256GB以上 |
| VRAM | 複数GPU(各40GB以上目安) |
| ストレージ | 高速ネットワーク対応 |
| 高速インターコネクト | NVLink、Infiniband、100G/200G Ethernet |
ハードウェア選定のポイント
AI/MLプロジェクトを成功させるためには、GPU単体の性能だけでなく、システム全体のバランス、電力効率、そして将来の拡張性を考慮した選定が重要です。
主要パーツであるGPUの選定に加えてCPUやメモリ、NVMeストレージなどシステム全体のバランスを整えることが学習スピードや処理効率に大きく影響します。複数GPU構成では電源や冷却設計の安定性が重要なため、リダンダント電源や80PLUS Platinumなどの高効率電源を採用することにより長時間の学習や推論も安心して行えます。 また、将来的なモデルの大型化に備え、十分なVRAM容量やGPU追加に対応できるシャーシの拡張性も検討材料となります。
柔軟なハードウェア構成の提供が弊社の強みです。AI用途に応じた計算負荷やモデル規模、ワークフローに合わせて安定性と効率を両立し、開発スピードを加速する最適なハードウェア選びをサポートします。
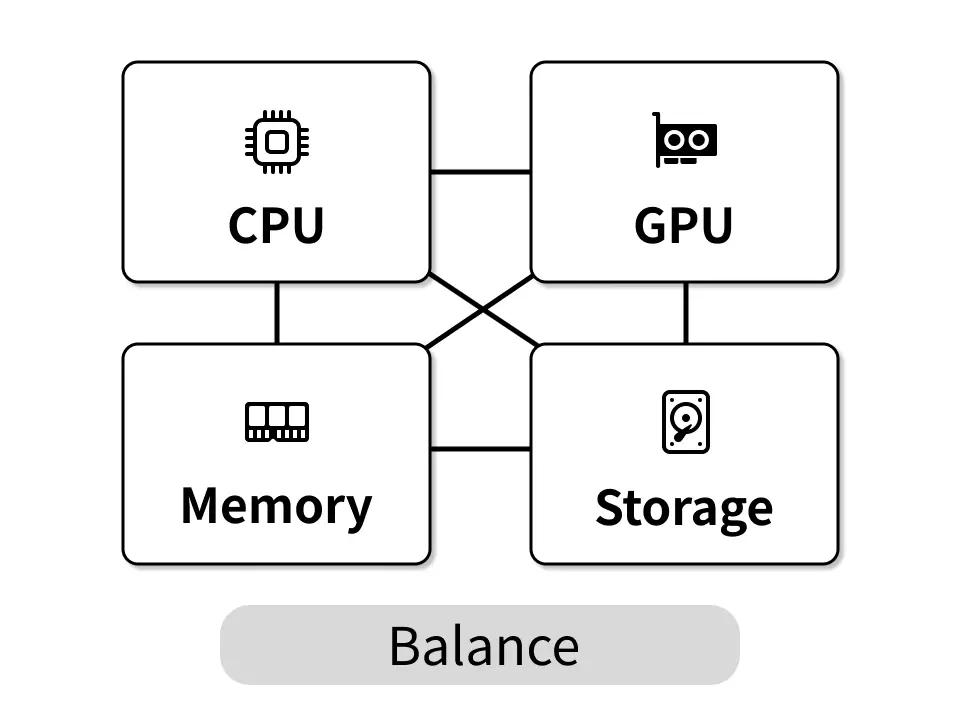
システム全体のバランス
GPU性能だけが高くてもCPUのコア数やメモリ帯域、ストレージ速度がボトルネックになると学習効率は大幅に低下します。各コンポーネントが協調して動作するバランスの良い構成が重要です。
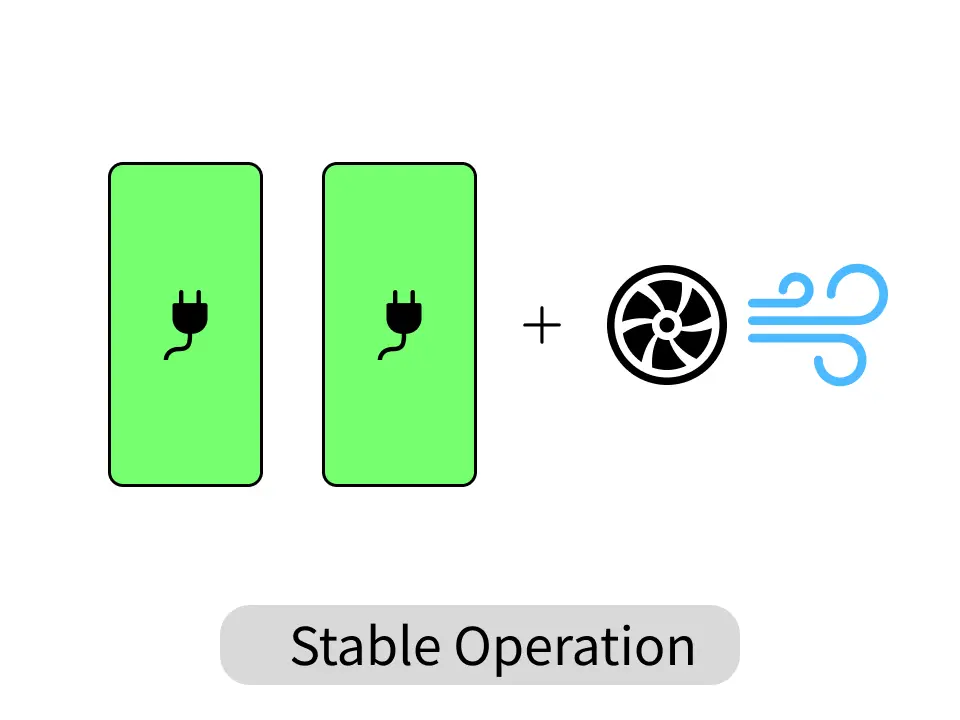
電源と冷却の重要性
ハイエンドGPUは大量の電力を消費し発熱します。200V環境に対応したリダンダント電源や効率的なエアフロー設計を持つシャーシを選ぶことで長時間負荷がかかる学習ジョブでも安定稼働を実現します。
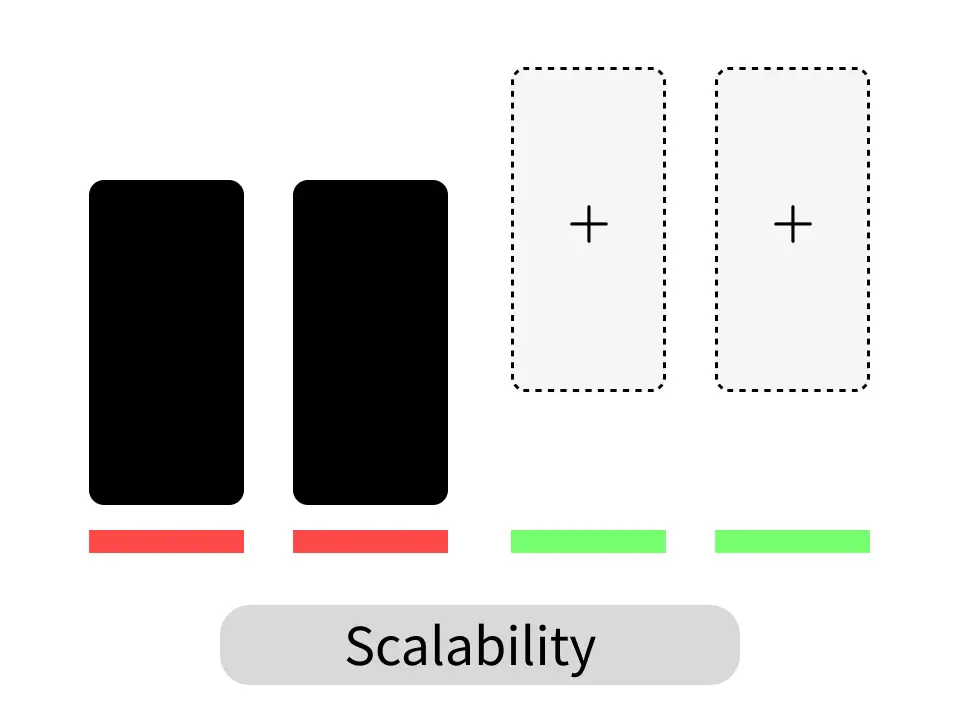
将来的な拡張性
モデルの大規模化に伴いVRAM容量不足が課題になることがあります。初期導入時は最小限でも将来的にGPUを増設可能なスロット数や電源容量に余裕のあるシステムを選ぶことがコスト効率の良い投資となります。
代表的なソフトウェア
AIプラットフォーム
CPU主体の構成からGPUを活用した高性能環境まで、AIの処理内容によって適したソフトウェア基盤は異なります。 弊社ではCUDAやROCmを含む主要フレームワークが動作する開発ベース環境を整備し、お客様がすぐに実験や開発を開始できる状態でご提供します。
さらに、NVIDIA社やAMD社提供の最新Dockerコンテナ環境の動作確認だけでなく、コンテナを使わずCondaを用いたPython環境での分離構築も可能です。これにより、各種ライブラリやバージョン違いの環境も柔軟に準備でき、開発者は状況に応じて最適な環境を選択できます。 下表では階層ごとの代表ソフトウェアと、必要となるハードウェアの傾向を整理しています。
Python
シンプルで分かりやすい構文の汎用プログラミング言語。Webアプリ、AI開発など幅広い分野で活用されています。
TensorFlow
Googleが開発した機械学習やディープラーニングのためのオープンソースライブラリ。AIモデルの構築、学習、実行に活用されています。
Hugging Face
世界中のAI研究者や開発者が機械学習モデルやデータセットを共有・活用できるオープンソース・コミュニティー。
Docker
アプリケーションとその実行に必要な環境を「コンテナ」にまとめて、どこでも同じように動かせるようにするプラットフォーム。
OS / プラットフォーム
AI開発環境の基盤。Linux系はGPUドライバやライブラリ対応が安定
| 推奨ハードウェア | ハイエンドGPU |
|---|---|
| 開発環境 | CUDA/ROCm |
| 料金体系 | 無償(Ubuntu) / 有償 |
| 導入難易度 | 中 |
| 活用分野 | 研究・開発・製造 |
言語 / ランタイム
フレームワークやライブラリの土台。AI・機械学習の標準言語として広く採用。
| 推奨ハードウェア | エンタープライズCPU |
|---|---|
| 開発環境 | CUDA/ROCm(GPU利用時) |
| 料金体系 | 無償 |
| 導入難易度 | 低 |
| 活用分野 | 研究・開発・教育・製造 |
フレームワーク
深層学習・モデル構築の中心。GPU最適化済みで幅広い用途に対応。
| 推奨ハードウェア | ハイエンドGPU |
|---|---|
| 開発環境 | CUDA/ROCm |
| 料金体系 | 無償 |
| 導入難易度 | 中~高 |
| 活用分野 | 研究・開発・製造 |
ライブラリ
幅広い分野に対応した膨大なモデル群やデータセットを共有、活用できるプラットフォーム
| 推奨ハードウェア | ハイエンドGPU |
|---|---|
| 開発環境 | CUDA/ROCm (GPU利用時) |
| 料金体系 | 無償 / 有償 |
| 導入難易度 | 中~高 |
| 活用分野 | IT・教育・広告 |
ライブラリ
クラシックな機械学習。CPUでも十分高速、GPU対応も可能。
| 推奨ハードウェア | ハイエンドGPU |
|---|---|
| 開発環境 | CUDA/ROCm |
| 料金体系 | 無償 |
| 導入難易度 | 低 |
| 活用分野 | 金融・教育・製造 |
アプリケーション / ツール
GUIでの数値解析・DL開発に対応。研究・制御分野で広く利用。
| 推奨ハードウェア | エンタープライズCPU |
|---|---|
| 開発環境 | CUDA/ROCm(GPU利用時) |
| 料金体系 | 有償 |
| 導入難易度 | 中 |
| 活用分野 | 研究・産業制御 |
運用 / MLOps
環境再現・モデル運用を支援。GPUコンテナ対応で効率的な配備が可能。
| 推奨ハードウェア | エンタープライズCPU+ハイエンドGPU |
|---|---|
| 開発環境 | CUDA/ROCm |
| 料金体系 | 無償 |
| 導入難易度 | 中~高 |
| 活用分野 | 研究・クラウド運用 |
関連製品
各種ラインナップとカスタマイズ
ここまでご紹介した要件や環境を踏まえ、弊社では用途や処理規模に応じて選べる各種GPUサーバー・ワークステーションを取り揃えています。 主要パーツに加え、電源・冷却設計、メモリ構成、NVMeストレージ構成なども、目的に合わせて柔軟にカスタマイズ可能です。 AI・機械学習の開発基盤をすぐに整えたい方には、弊社のGPUサーバー・ワークステーションをご活用いただけます。
ぜひお気軽にお問い合わせください。



