



画像は実際の製品と異なる場合があります。
NVIDIA GPU 最大2基搭載
VCAE-2U12HA004-G
2 基
32 枚
2 基
12 ベイ
2U
冗長電源
10GbE
主な仕様
- AMD EPYC™ 7003 シリーズ・プロセッサー 2基 搭載 ( Milan / Socket SP3 )
- DDR4-3200 メモリ 32スロット
- 2スロット PCIe GPU 最大2基 搭載可能
- AMD Instinct™ アクセラレーター 搭載可能
- 3.5 インチ ホットスワップ 12ベイ
- 10 ギガビット イーサネット 2ポート
- 2U ラックマウントサーバー
- リダンダント電源搭載


製品特長
2UラックマウントシャーシにNVIDIA GPUを最大2基搭載するGPGPUモデルです。
本製品は、AMD 第3世代 EPYC プロセッサーを2基搭載し高いマルチスレッド性能とPCIe 4.0接続の高速なネットワーク帯域幅により高密度なGPUコンピュートノードを構築することが可能でTCOを大幅に削減します。
AMD EPYC™ 7003 シリーズ・プロセッサー 搭載
AMD EPYC™ 7003 シリーズ・プロセッサー
「AMD EPYC プロセッサー」はデータセンター向けプロセッサーとして第1世代である「EPYC 7001 シリーズ」が2017年にリリースされました。第1世代 EPYCでは複数のダイを単一のパッケージに統合したマルチダイ化によりコストを抑え、性能向上のためのアプローチとしてMCM(Multi Chip Module:マルチ・チップ・モジュール)構成を採用、「Infinity Fabric」と呼ばれるインターコネクト技術により4つのダイが接続されています。
これにより第1世代 EPYCでは8個のZEN CPUコアを搭載したダイを4個使うことで最大32コアのCPUを実現しています。
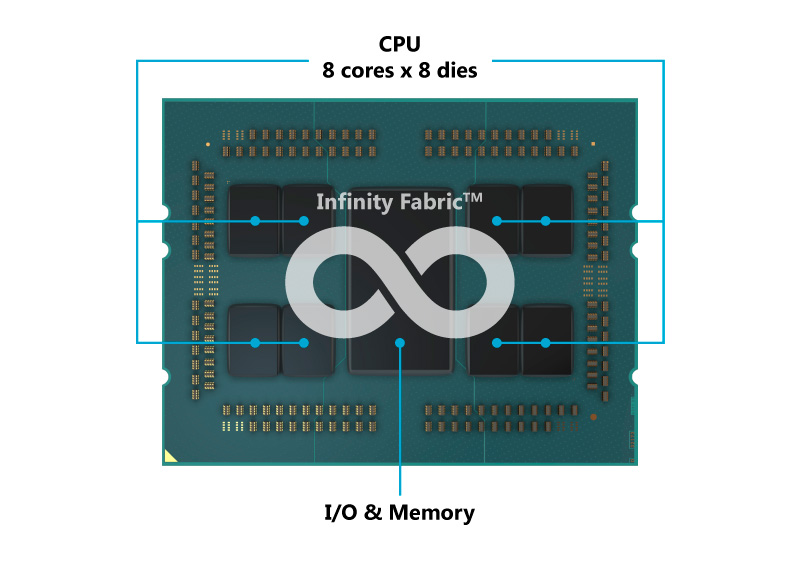
2019年にリリースされた第2世代 EPYC プロセッサー「EPYC 7002 シリーズ」は、第1世代 EPYCのMCM構成を継承。8個のZEN2 CPUコアを搭載したダイを最大8個搭載し、新たにPCI Express Gen4のコントローラ、8チャネルのメモリコントローラなどを一つに集約したI/Oダイを接続。8コア×8ダイで最大64個のCPUコアを単一のCPUパッケージに搭載しています。
第3世代であるEPYC 7003シリーズ(Milan)はアーキテクチャを「Zen3」に刷新、メモリチャネルがこれまでの4,8チャネルに加え、6チャネルの動作もサポート。32MBのL3キャッシュを8コアで共有することでレイテンシが大幅に軽減するよう変更され、IPCは前世代との比較で最大19%向上しています。また、セキュリティ機能も拡張され安全性も強化されています。
プラットフォームは第2世代とソケット互換のため、既存システムのファームウェアをアップデートすることで第3世代にアップグレードすることが可能となっています。
| 第3世代 EPYC 7003 | 第2世代 EPYC 7002 | 第1世代 EPYC 7001 | |
|---|---|---|---|
| リリース年 | 2021年 | 2019年 | 2017年 |
| コードネーム | Milan | Rome | Naples |
| アーキテクチャ | Zen3 | Zen2 | Zen |
| 製造プロセスルール | 7nm | 7nm | 14nm |
| 最大CPUコア | 64 | 64 | 32 |
| CPUソケット | SP3 | SP3 | SP3 |
| Infinity Fabric | 18GT/秒 | 18GT/秒 | 10.7GT/秒 |
| ソケット数 | 1 / 2 | 1 / 2 | 1 / 2 |
| メモリ | DDR4-3200 | DDR4-3200 | DDR4-2666 |
| メモリチャネル | 8 | 8 | 8 |
| 最大メモリ | 4TB | 4TB | 2TB |
| PCI Express | Gen4 128レーン | Gen4 128レーン | Gen3 128レーン |
8コアから64コアまでの幅広いラインナップ
AMD 第3世代 EPYC プロセッサーは1ソケットで最大64コアのメニーコアをもち、優れた価格性能比を実現します。パフォーマンスと消費電力のバランスが良くコストパフォーマンスに優れるBalanced & Optimizedのほか、コアあたりのシングルスレッド性能を重視したCore Performance、メニーコアでのマルチスレッド性能を重視したCore Densityの3つのセグメントからニーズに合わせた幅広い選択が可能です。
進化した「ZEN3」アーキテクチャ

第3世代 EPYCは前世代より製造プロセス、最大コア数などに大きな変化はないものの、新しいアーキテクチャ「ZEN3」に刷新されており、第2世代 EPYCに採用されていた「Zen2」と比較すると、IPC(Instruction Per Clock-cycle)が最大19%ほど改善されています。
アーキテクチャが新しくなったことにより、8つのCPUコアが32MBのL3キャッシュを共有し1コアあたりが使えるL3キャッシュが増加しているほか、6チャンネルのメモリチャネルをサポート。これによりメモリ構成が柔軟に選択でき、導入におけるコスト削減に貢献しています。
このほか、セキュリティ面も強化されており「AMD Infinity Guard」と呼ばれるセキュリティ機能を搭載、新たに「SEV-SNP」「Shadow Stack」機能が追加され仮想マシン環境の安全性を引き上げています。
AMD EPYC™ 7003 シリーズ・プロセッサー 一覧
| CPU | コア/スレッド | 基本周波数 | 最大周波数 | 最大ソケット数 | メモリ | L3 キャッシュ | TDP |
| EPYC 7773X | 64C/128TH | 2.2GHz | 3.5GHz | 2S | DDR4-3200MHz | 768MB | 280W |
| EPYC 7763 | 64C/128TH | 2.45GHz | 3.5GHz | 2S | DDR4-3200MHz | 256MB | 280W |
| EPYC 7713P | 64C/128TH | 2.GHz | 3.675GHz | 1S | DDR4-3200MHz | 256MB | 225W |
| EPYC 7713 | 64C/128TH | 2.GHz | 3.675GHz | 2S | DDR4-3200MHz | 256MB | 225W |
| EPYC 7663 | 56C/112TH | 2.GHz | 3.5GHz | 2S | DDR4-3200MHz | 256MB | 240W |
| EPYC 7643 | 48C/96TH | 2.3GHz | 3.6GHz | 2S | DDR4-3200MHz | 256MB | 225W |
| EPYC 7573X | 32C/64TH | 2.8GHz | 3.6GHz | 2S | DDR4-3200MHz | 768MB | 280W |
| EPYC 75F3 | 32C/64TH | 2.95GHz | 4.0GHz | 2S | DDR4-3200MHz | 256MB | 280W |
| EPYC 7543P | 32C/64TH | 2.8GHz | 3.7GHz | 1S | DDR4-3200MHz | 256MB | 225W |
| EPYC 7543 | 32C/64TH | 2.8GHz | 3.7GHz | 2S | DDR4-3200MHz | 256MB | 225W |
| EPYC 7513 | 32C/64TH | 2.6GHz | 3.65GHz | 2S | DDR4-3200MHz | 128MB | 200W |
| EPYC 7473X | 24C/48TH | 2.8GHz | 3.7GHz | 2S | DDR4-3200MHz | 768MB | 240W |
| EPYC 7453 | 28C/56TH | 2.75GHz | 3.45GHz | 2S | DDR4-3200MHz | 64MB | 225W |
| EPYC 74F3 | 24C/48TH | 3.2GHz | 4.0GHz | 2S | DDR4-3200MHz | 256MB | 240W |
| EPYC 7443P | 24C/48TH | 2.85GHz | 4.0GHz | 1S | DDR4-3200MHz | 128MB | 200W |
| EPYC 7443 | 24C/48TH | 2.85GHz | 4.0GHz | 2S | DDR4-3200MHz | 128MB | 200W |
| EPYC 7413 | 24C/48TH | 2.65GHz | 3.6GHz | 2S | DDR4-3200MHz | 128MB | 180W |
| EPYC 7373X | 16C/32TH | 3.05GHz | 3.8GHz | 2S | DDR4-3200MHz | 768MB | 240W |
| EPYC 73F3 | 16C/32TH | 3.5GHz | 4.0GHz | 2S | DDR4-3200MHz | 256MB | 240W |
| EPYC 7343 | 16C/32TH | 3.2GHz | 3.9GHz | 2S | DDR4-3200MHz | 128MB | 190W |
| EPYC 7313P | 16C/32TH | 3.0GHz | 3.7GHz | 1S | DDR4-3200MHz | 128MB | 155W |
| EPYC 7313 | 16C/32TH | 3.0GHz | 3.7GHz | 2S | DDR4-3200MHz | 128MB | 155W |
| EPYC 72F3 | 8C/16TH | 3.7GHz | 4.1GHz | 2S | DDR4-3200MHz | 256MB | 180W |
関連製品

NVIDIA データセンターGPU Ampere世代 搭載可能
NVIDIA Ampere

販売終了 |

販売終了 |

販売終了 |

|

|

|
|
|---|---|---|---|---|---|---|
| GPUメモリ | 80GB HBM2e | 48GB GDDR6 | 24GB HBM2 | 4x 16GB GDDR6 | 24GB GDDR6 | 16GB GDDR6 |
| メモリー帯域幅 | 1,935GB/s | 696GB/s | 933GB/s | 200GB/s | 600GB/s | 200GB/s |
| 最大消費電力 | 300W | 300W | 165W | 250W | 150W | 40W-60W(初期設定60W) |
| マルチインスタンスGPU | 最大7GPU | N/A | 4GPU 6GB 2GPU 12GB 1GPU 24GB |
N/A | N/A | N/A |
| フォームファクター | PCIe 2スロット |
2スロット FHFL |
2スロット FHFL |
2スロット FHFL |
1スロット FHFL |
1スロット LP |
| NVLink | NVIDIA NVLink 600 GB/s
PCIe Gen4 64 GB/s |
2 ウェイ ロー プロファイル (2 スロット) |
NVIDIA NVLink 200 GB/s
PCIe Gen4 64 GB/s |
N/A | N/A | N/A |
| 排熱機構 | パッシブ(冷却ファンなし) | パッシブ(冷却ファンなし) | パッシブ(冷却ファンなし) | パッシブ(冷却ファンなし) | パッシブ(冷却ファンなし) | パッシブ(冷却ファンなし) |
| FP64(TFLOPS) | 9.7 | 0.58464 | 5.2 | 4x 0.00702 | – | 0.11702 |
| FP64 Tensorコア(TFLOPS) | 19.5 | – | 10.3 | – | – | – |
| Tensor Float 32(TFLOPS) | 156 / 312 | 74.8 / 149.6 | 82 / 165 | 4×9 / 4x 18 | 62.5 / 125 | 9 / 18 |
| BFLOAT16 Tensorコア(TFLOPS) | 312 / 624 | 149.7 / 299.4 | 165 / 330 | 4x 17.9 / 4x 35.9 | 125 / 250 | 18 / 36 |
| FP16 Tensorコア(TFLOPS) | 312 / 624 | 149.7 / 299.4 | 165 / 330 | 4x 17.9 / 4x 35.9 | 125 / 250 | 18 / 36 |
| INT8 Tensorコア(TOPS) | 624 / 1248 | 299.3 / 598.6 | 330 / 661 | 4×35.9 / 4x 71.8 | 250 / 500 | 36 / 72 |
| 実アプリ性能 | 90% | – | – | – | – | – |
NVIDIA Ampere アーキテクチャ
NVIDIA A100 Tensorコア GPUはあらゆる規模で前例のない高速化を実現し、世界最高のパフォーマンスを誇るエラスティック データ センターにAI、データ分析、HPCのためのパワーを与えます。NVIDIA Ampereアーキテクチャで設計されたNVIDIA A100は、NVIDIA データ センター プラットフォームのエンジンです。A100は、前世代と比較して最大20倍のパフォーマンスを発揮し、7つのGPUインスタンスに分割して、変化する需要に合わせて動的に調整できます。40GBと80GB のメモリ バージョンで利用可能なA100 80GBは、毎秒2テラバイト (TB/秒)超えの世界最速メモリ帯域幅を実現し、最大級のモデルやデータセットを解決します。

NVIDIA Ampere アーキテクチャのイノベーション
第3世代 Tensorコア
NVIDIA Volta™ アーキテクチャで最初に導入されたNVIDIA Tensorコア テクノロジは、AIに劇的な高速化をもたらしました。トレーニング時間を数週間から数時間に短縮し、推論を大幅に加速します。NVIDIA Ampereアーキテクチャはこのイノベーションを基盤としており、新しい精度である Tensor Float 32 (TF32) と64ビット浮動小数点 (FP64) を導入することで、AI の導入を加速して簡素化し、Tensor コアのパワーを HPC にもたらします。
TF32はFP32と同じように動作しますが、コードを変更しなくても、AIを最大20倍スピードアップします。 NVIDIA Automatic Mixed Precisionを使用すると、研究者はわずか数行のコードを追加するだけで、自動混合精度とFP16でさらに2倍のパフォーマンスを得られます。また、bfloat16、INT8、INT4に対応しているので、NVIDIA Ampere アーキテクチャのTensorコア GPUのTensorコアは、AIのトレーニングと推論の両方に対する、非常に汎用性の高いアクセラレータです。また、TensorコアのパワーをHPCにもたらすA100およびA30 GPUでは、完全なIEEE準拠のFP64精度での行列演算を実行できます。
Multi-Instance GPU (MIG)
あらゆるAIとHPC アプリケーションがアクセラレーションの恩恵を受けることができますが、すべてのアプリケーションがGPUのフル パフォーマンスを必要とするわけではありません。Multi-Instance GPU (MIG) は、 A100とA30 GPU PU でサポートされている機能であり、ワークロードがGPUを共有することを可能にします。MIGを利用すると、各GPUを複数のGPUインスタンスに分割できます。各インスタンスは完全に分離され、ハードウェア レベルで保護され、専用の高帯域幅メモリ、キャッシュ、コンピューティング コアを与えられます。これにより開発者は、大小を問わずあらゆるアプリケーションに対して画期的な高速化を利用できるようになり、サービス品質も保証されます。また、IT管理者は、適切なサイズのGPUアクセラレーションを提供することで利用率を最適化し、ベアメタル環境と仮想化環境の両方ですべてのユーザーとアプリケーションにアクセスを拡張できます。
第3世代の NVLink
アプリケーションをマルチGPUでスケールさせるには、非常に高速にデータを移動させる必要があります。NVIDIA Ampere アーキテクチャの第3世代 NVIDIA® NVLink® は、GPU 間の直接帯域幅を2倍の毎秒600ギガバイト (GB/s) にします。これは、PCIe Gen4の約10倍です。最新世代の NVIDIA NVSwitch™と組み合わせることで、サーバー内のすべてのGPUが完全なNVLinkの速度で相互に通信し、驚くほど高速なデータ転送が可能になります。 NVIDIA DGX™A100と他の主要なコンピューター メーカーのサーバーは、 NVIDIA HGX™ A100ベースボードを介してNVLinkとNVSwitchのテクノロジを活用し、HPCおよびAIのワークロードに優れたスケーラビリティを提供します。
スパース構造
現代のAIネットワークは大きく、数百万、場合によっては数十億のパラメーターを持ち、ますますその規模は拡大しています。これらのパラメーターのすべてが正確な予測や推論に必要なわけではなく、一部のパラメーターをゼロに変換することで、精度を下げることなくモデルを「スパース」にできます。Tensorコアでは、スパースなモデルのパフォーマンスを最大2倍にできます。スパース機能はAI推論で特に効果を発揮しますが、モデルトレーニングのパフォーマンス向上にも利用できます。
第2世代 RTコア
NVIDIA A40のNVIDIA Ampereアーキテクチャの第2世代RTコアは、映画コンテンツのフォトリアルなレンダリング、建築デザインの評価、製品デザインのバーチャル試作品などのワークロードを大幅にスピードアップします。RTコアはまた、レイ トレーシングされたモーション ブラーのレンダリングをスピードアップし、短時間で結果が得られ、ビジュアルの精度が上がります。さらに、レイ トレーシングをシェーディング機能またはノイズ除去機能と共に同時に実行できます。
よりスマートで高速なメモリ
A100は、データセンターでの膨大な量のコンピューティングを可能にします。コンピューティング エンジンを常に完全に活用するために、A100はこのクラスで最大となる毎秒2テラバイト (TB/s) のメモリ帯域幅を備えています。前世代の2倍以上です。さらに、A100は前世代の7倍となる40メガバイト (MB) のレベル2キャッシュを含む、より大きなオンチップ メモリを搭載しており、コンピューティング パフォーマンスを最大限まで引き上げます。
関連製品




NVIDIA RTX™ Ampere世代 搭載可能
NVIDIA RTX™ Ampere

|

販売終了 |

販売終了 |

販売終了 |

販売終了 |

販売終了 |

販売終了 |

|

|
|
|---|---|---|---|---|---|---|---|---|---|
| GPUメモリ | 40GB HBM2 | 48GB GDDR6 | 24GB GDDR6 | 24GB GDDR6 | 20GB GDDR6 | 16GB GDDR6 | 12GB GDDR6 | 8GB GDDR6 | 4GB GDDR6 |
| メモリー帯域幅 | 1,555GB/s | 768GB/s | 768GB/s | 768GB/s | 640GB/s | 448GB/s | 288GB/s | 192GB/s | 96GB/s |
| ECC | Yes | Yes | Yes | Yes | Yes | Yes | Yes | – | – |
| CUDAコア | 6,912 | 10,752 | 10,240 | 8,192 | 7,168 | 6,144 | 3,328 | 2,304 | 768 |
| Tensorコア | 432 | 336 | 320 | 256 | 224 | 192 | 104 | 72 | 24 |
| RTコア | N / A | 84 | 80 | 64 | 56 | 48 | 26 | 18 | 6 |
| 単精度性能(TFLOPS) | 19.5 | 38.7 | 34.1 | 27.8 | 23.7 | 19.2 | 8.0 | 6.7 | 2.7 |
| RTコア性能(TFLOPS) | N / A | 75.6 | 66.6 | 54.2 | 46.2 | 37.4 | 15.6 | 13.2 | 5.4 |
| Tensor性能(TFLOPS) | 623.8 | 309.7 | 272.8 | 222.2 | 189.2 | 153.4 | 63.9 | 53.8 | 21.7 |
| NVLink | Yes | Yes | Yes | Yes | Yes | N / A | N / A | N / A | N / A |
| NVLink帯域幅 | 400GB/s | 112.5GB/s (双方向) |
112.5GB/s (双方向) |
112.5GB/s (双方向) |
112.5GB/s (双方向) |
N / A | N / A | N / A | N / A |
| システムインターフェイス | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x8 | PCIe 4.0 x8 |
| 最大消費電力 | 240W | 300W | 230W | 230W | 200W | 140W | 70W | 50W | 50W |
| 排熱機構 | アクティブ | アクティブ | アクティブ | アクティブ | アクティブ | アクティブ | アクティブ | アクティブ | アクティブ |
| フォームファクター | 4.4″ H x 10.5″ L 2スロット |
4.4″ H x 10.5″ L 2スロット フルハイト |
4.4″ H x 10.5″ L 2スロット フルハイト |
4.4″ H x 10.5″ L 2スロット フルハイト |
4.4″ H x 10.5″ L 2スロット フルハイト |
4.4″ H x 9.5″ L 1スロット |
2.7″ H x 6.6″ L 2スロット |
2.7″ H x 6.4″ L 1スロット |
2.7″ H x 6.4″ L 1スロット |
| 画面出力 | N / A | DisplayPort 1.4a x4 | DisplayPort 1.4a x4 | DisplayPort 1.4a x4 | DisplayPort 1.4a x4 | DisplayPort 1.4a x4 | mDP 1.4a x4 | mDP 1.4a x4 | mDP 1.4a x4 |
| 電源コネクタ | 16ピン PCIe CEM5 x1 | 8ピン CPU x1 | 8ピン PCIe x1 | 8ピン PCIe x1 | 8ピン PCIe x1 | 6ピン PCIe x1 | N / A | N / A | N / A |
NVIDIA RTX テクノロジ
NVIDIA RTX™ テクノロジは、コンピューターグラフィックスにおけるNVIDIAの最も重要な進歩の1つであり、かつてないスピードで実世界をシミュレートする 新世代アプリケーションをもたらします。AI、レイ トレーシング、シミュレーションにおける最新技術が盛り込まれたRTXテクノロジによって驚異的な3Dデザイン、フォトリアルなシミュレーション、圧倒的なビジュアルエフェクトが、かつてないほど高速で実現します。

中心となるテクノロジ
レイ トレーシング
RTXテクノロジはNVIDIA OptiX™、Microsoft DXR、Vulkanといった、最適化されたレイトレーシングAPIにより、映画品質の映像をリアルタイムでレンダリングするという夢を叶えるものです。極めて正確な影、反射、屈折の描写で、フォトリアルなオブジェクトと環境をリアルタイムでレンダリングできるため、アーティストやデザイナーは驚異的な作品をこれまでにない速さで作り出せるようになりました。
人工知能 (AI)
NVIDIA RTXテクノロジはAIのパワーをビジュアル コンピューティングにもたらします。かつてないワークフローの高速化をエンド ユーザーにもたらすAI強化アプリケーションを開発できます。インテリジェントな画像の編集、繰り返しタスクの自動化、コンピューティング負荷の高いプロセスの最適化により、時間とリソースを節約し、アーティストやデザイナーの創作を劇的に加速します。
ラスタライゼーション
RTXテクノロジには、可変レート シェーディング、テクスチャスペース シェーディング、マルチビュー レンダリングなどのプログラミング可能シェーディングにおける最新技術が盛り込まれています。より豊かなビジュアルの制作と大規模なモデルやシーンとのよりスムーズなインタラクティブ性を実現しVR体験が改善されます
シミュレーション
現実感あふれるビジュアルを生み出すには、外観だけでなく、その挙動も重要です。CUDA® コアのパワーと、NVIDIA PhysX®、Flow、FleX、CUDAなどのAPIによりRTXテクノロジではゲーム、仮想環境、特殊効果といったあらゆるケースで、実世界の物体の挙動を正確にモデリングできます。
関連製品




AMD Instinct™ アクセラレーター 搭載可能
AMD Instinct™ アクセラレーター
AMD Instinct™ MI200 シリーズ・アクセラレーター(CDNA2)は、AMD によるデータセンター向けGPU であり最新の AMD CDNA™ 2 アーキテクチャーをベースにマトリックス・コア・テクノロジーで設計されています。最大規模のエクサスケール・システムを含め、メインストリームのサーバーやスーパーコンピューターにおける発見を加速するように設計されており、HPCや AI などのワークロードを大幅に高速化して、新たな発見を加速します。
また、AMD Infinity Fabric™ テクノロジーは AMD EPYC™ CPUからGPU アクセラレーターへの直接接続を可能にし、統合された最新のサーバー・パフォーマンスを実現することが可能となります。

|
|
|---|---|
| GPU アーキテクチャ | CDNA2 |
| 演算ユニット | 104 |
| ストリーミングプロセッサ | 6,656 |
| 倍精度演算性能(FP64) | 22.6 TFLOPS |
| 単精度演算性能(FP32) | 22.6 TFLOPs |
| 半精度演算性能(FP16) | 181 TFLOPs |
| GPUメモリ | 64 GB HBM2e |
| メモリ帯域幅 | 1638.4 GB/sec |
| ECC | 対応 |
| システム接続 | PCI Express 4.0 x16 |
| フォームファクタ | PCIe Full Height / Length:10.5″ 2スロット |
| 最大消費電力 | 300 W |
| 冷却方式 | パッシブ(冷却ファンなし) |
| プログラミング環境 | ISO C++, OpenCL™, ROCm™ Open Ecosystem Python5 (via Anaconda’s NUMBA) |
関連製品

製品仕様
| CPU |
AMD EPYC 7003 シリーズ・プロセッサー
x 2
AMD EPYC 7003 シリーズ・プロセッサー
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| チップセット | System on Chip ( SoC ) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| メモリ | DDR4-3200MHz ECC RDIMM / 3DS RDIMM x 32 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ドライブベイ |
3.5インチ ホットスワップ ( SATA 対応 )
x 12
or 3.5インチ ホットスワップ ( SAS 対応 ) x 12 オプション or 3.5インチ ホットスワップ ( SATA 対応 ) x 8 + 3.5インチ ホットスワップ ( NVMe 対応 ) x 4 オプション |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| オプティカルドライブ | USB接続 外付けDVDマルチドライブ オプション | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| グラフィックス | オンボード | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GPU | 2スロット GPU 最大 x 2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ネットワークI/F | 10ギガビット イーサネット ( RJ45 ) x 2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 管理I/F | BMC / IPMI 2.0 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| I/Oポート 背面 |
シリアルポート
x 1
VGA x 1 USB3.0 x 2 IPMI用 MLAN ( RJ45 ) x 1 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 拡張スロット |
PCI Express 4.0 x16 ( FH,10.5″L )
x 2
PCI Express 4.0 x16 ( FH,9.5″L ) x 1 PCI Express 4.0 x16 ( LP ) x 1 PCI Express 4.0 x8 ( FH,9.5″L / x16スロット形状 ) x 1 PCI Express 4.0 x8 ( LP / x16スロット形状 ) x 1 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ケース | 2Uラックマウントケース : W 437mm x H 89mm x D 723mm | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 電源 | 100V 1000W / 200V 1600W リダンダント電源 80-plus Titanium | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OS |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 保守 |
1年間全国出張オンサイトサービス
3年間全国出張オンサイト オプション |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 動作推奨環境 |
温度 : 10 ℃ ~ 35 ℃ (GPU搭載時は25℃)
湿度 : 20 % ~ 80 % (結露なきこと) |
カタログ
商標について
- Intel、インテル、Intel ロゴ、Intel Inside、Intel Inside ロゴ、Intel Atom、Intel Atom Inside、Intel Core、Core Inside、Intel vPro、vPro Inside、Celeron、Celeron Inside、Itanium、Itanium Inside、Pentium、Pentium Inside、Xeon、Xeon Phi、Xeon Inside、Ultrabook は、アメリカ合衆国および/またはその他の国におけるIntel Corporation の商標です。
- AMD、AMD EPYC™、AMD Ryzen™ 、AMD Radeon™ 、Radeon Instinct™ は、アメリカ合衆国および/またはその他の国におけるAdvanced Micro Devices,Incの商標です。
- NVIDIA、NVIDIA のロゴ、GeForce、 CUDA、 NVLINK、SLI、Tesla、Quadro、および SHIELD は、米国またはその他の国における NVIDIA Corporation の商標または登録商標です
- Supermicroは商標であり、米国のSuper Micro Computer, Inc.およびその他の国における子会社の登録商標です。
- Red Hat、Red Hat Enterprise Linux、Shadowmanロゴ、JBossは米国およびその他の国において登録されたRed Hat, Inc.の商標です。
- Linux(R)は米国およびその他の国におけるLinus Torvaldsの登録商標です。
- SUSEおよびSUSEロゴは、米国およびその他の国におけるSUSE LLCの登録商標です。
- VMwareおよびVMwareの製品名は、VMware, Inc.の米国および各国での商標または登録商標です。
- Microsoft、Windows、MS-DOS、Windows NT、Windows Vista、Windows Server、Windows Azure、SQL Serverおよび Microsoft Exchange Serverまたはその他のマイクロソフト製品の名称および製品名は、米国 Microsoft Corporation の、米国およびその他の国における商標または登録商標です。
- UNIXは、米国およびその他の国におけるオープン・グループの登録商標です。
- その他弊社ウェブサイト(本サイト)に表示・記載されている会社名、製品名およびロゴ等は、各社の登録商標または商標です。
