



画像は実際の製品と異なる場合があります。
AMD 第5世代 EPYC プロセッサー搭載
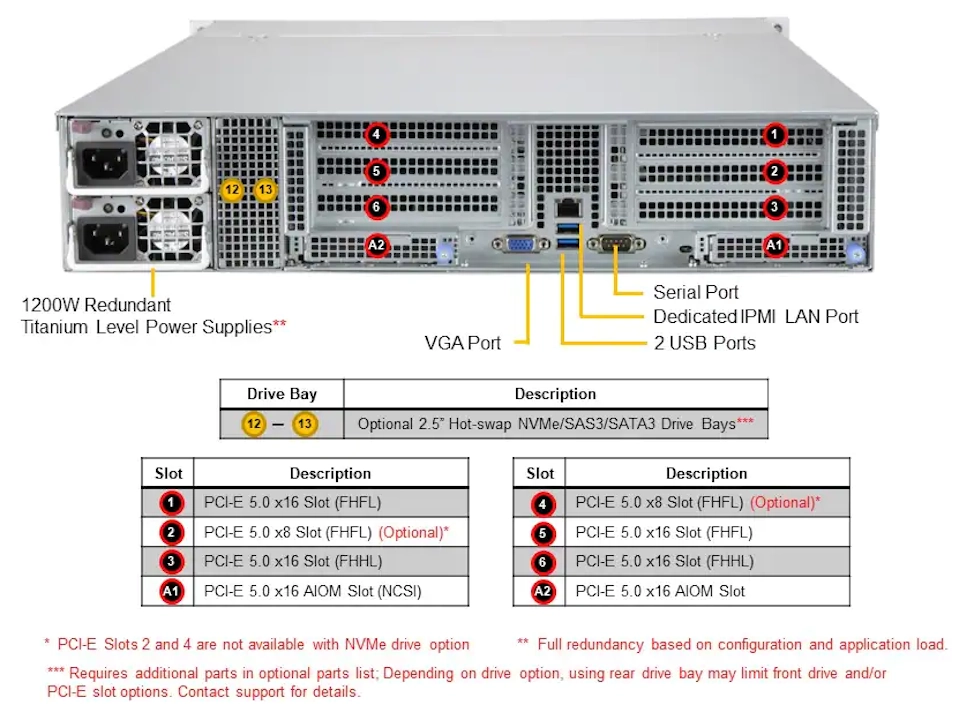
VCAE-2USR12H1301
1 基
12 枚
2 基
12 ベイ
2 枚
2U
冗長電源
10GbE
主な仕様
- AMD EPYC™ 9005 シリーズ・プロセッサー 1基 搭載
( Turin / Socket SP5 ) - DDR5-6000 メモリ 12スロット
- 2スロット PCIe GPU 最大2基 搭載可能
- NVIDIA L40S 搭載可能
- 3.5 インチ ホットスワップ 12ベイ
- M.2 SSD 最大2枚 搭載可能
- 10 ギガビット イーサネット 2ポート
- 2U ラックマウントサーバー
- リダンダント電源搭載


製品特長
2UラックマウントシャーシにAMD 第5世代 EPYC プロセッサーを1基、3.5インチ ドライブを最大12台、12本のDIMMを搭載。
「AMD EPYC 9005シリーズ・プロセッサー(Turin)」はデータセンター、クラウド、AIのワークロードを高速化し、エンタープライズ・コンピューティングのパフォーマンスを新たなレベルに引き上げます。
これにより既存のサーバーより非常に高いパフォーマンスを発揮し消費電力とサーバー設置数を削減させることが可能で、運用コストやエネルギー効率の向上が期待できます。
AMD EPYC™ 9005 シリーズ・プロセッサー 搭載
AMD EPYC™ 9005 シリーズ・プロセッサー
「AMD EPYC 9005シリーズ・プロセッサー(Turin)」はAMDのデータセンター向けプロセッサーである「EPYC シリーズ」の第5世代となります。CPUのアーキテクチャは最新のZen 5世代に強化され「Zen 5」はTSMCの4nm、「Zen 5c」はTSMCの3nmでそれぞれ製造され、前者は最大128コア、後者は192コアの製品が用意されています。Zen 4からの改良によりエンタープライズやクラウド向けで最大17%、HPCやAI向けで最大37%ほど向上しています。
Zen 5とZen 5cの違いはCPUコアあたりのL3キャッシュ容量であり、Zen 5が1コアあたり4MB、Zen 5cは1コアあたり2MBとなります。
また、前世代同様「SP5ソケット」を採用しており、BIOSやファームウエアのアップデートは必要となるものの、前世代と互換性を有しており既存システムでの利用が可能です。
最大コア数は192コアとなり、SKUにより最大周波数は5GHzに達します。メモリは最大12チャンネルで、DDR5-6000まで対応。2ソケットでは160レーンまでのPCI Express 5.0に対応しているほか、CXL 2.0にも対応しています。

「AMD EPYC 9005シリーズ・プロセッサー(Turin)」はデータセンター、クラウド、AIのワークロードを高速化し、エンタープライズ・コンピューティングのパフォーマンスを新たなレベルに引き上げます。
これにより既存のサーバーより非常に高いパフォーマンスを発揮し消費電力とサーバー設置数を削減させることが可能で、運用コストやエネルギー効率の向上が期待できます。
| 第5世代 EPYC 9005 | 第4世代 EPYC 9004 | 第3世代 EPYC 7003 | 第2世代 EPYC 7002 | 第1世代 EPYC 7001 | |
|---|---|---|---|---|---|
| リリース年 | 2024年 | 2023年/2022年 | 2021年 | 2019年 | 2017年 |
| コードネーム | Turin | Bergamo/Genoa/Genoa-X | Milan | Rome | Naples |
| アーキテクチャ | Zen5c/Zen5 | Zen4c/Zen4 | Zen3 | Zen2 | Zen |
| 製造プロセスルール | 3nm/4nm | 5nm | 7nm | 7nm | 14nm |
| 最大CPUコア | 192/128 | 128/96 | 64 | 64 | 32 |
| CPUソケット | SP5 | SP5 | SP3 | SP3 | SP3 |
| Infinity Fabric | – | 18GT/秒 | 18GT/秒 | 18GT/秒 | 10.7GT/秒 |
| ソケット数 | 1 / 2 | 1 / 2 | 1 / 2 | 1 / 2 | 1 / 2 |
| メモリ | DDR5-6000 | DDR5-4800 | DDR4-3200 | DDR4-3200 | DDR4-2666 |
| メモリチャネル | 12 | 12 | 8 | 8 | 8 |
| 最大メモリ | 6TB | 6TB | 4TB | 4TB | 2TB |
| PCI Express | Gen5 128レーン(1ソケット) Gen5 160レーン(2ソケット) |
Gen5 160レーン | Gen4 128レーン | Gen4 128レーン | Gen3 128レーン |
AMD EPYC™ 9005 シリーズ・プロセッサー 一覧
関連製品




AMD EPYC™ 9004 シリーズ・プロセッサー 搭載
AMD EPYC™ 9004 シリーズ・プロセッサー
「AMD EPYC プロセッサー」はデータセンター向けプロセッサーとして第1世代である「EPYC 7001 シリーズ」が2017年にリリースされました。第1世代 EPYCでは複数のダイを単一のパッケージに統合したマルチダイ化によりコストを抑え、性能向上のためのアプローチとしてMCM(Multi Chip Module:マルチ・チップ・モジュール)構成を採用、「Infinity Fabric」と呼ばれるインターコネクト技術により4つのダイが接続されています。これにより第1世代 EPYCでは8個のZEN CPUコアを搭載したダイを4個使うことで最大32コアのCPUを実現しています。
2019年にリリースされた第2世代 EPYC プロセッサー「EPYC 7002 シリーズ」は、第1世代 EPYCのMCM構成を継承。8個のZEN2 CPUコアを搭載したダイを最大8個搭載し、新たにPCI Express Gen4のコントローラ、8チャネルのメモリコントローラなどを一つに集約したI/Oダイを接続。8コア×8ダイで最大64個のCPUコアを単一のCPUパッケージに搭載しています。
第3世代であるEPYC 7003シリーズはアーキテクチャを「Zen3」に刷新、メモリチャネルがこれまでの4,8チャネルに加え、6チャネルの動作もサポート。32MBのL3キャッシュを8コアで共有することでレイテンシが大幅に軽減するよう変更され、IPCは前世代との比較で最大19%向上しています。また、セキュリティ機能も拡張され安全性も強化されています。
プラットフォームは第2世代とソケット互換のため、既存システムのファームウェアをアップデートすることで第3世代にアップグレードすることが可能となっています。

第4世代である9004シリーズ(Bergamo/Genoa/Genoa-X)では製造プロセスルールが5nmに微細化されたアーキテクチャ「Zen4」を採用。パッケージのサイズが前世代より大きくなり、最大128個のCPUを1パッケージに搭載が可能となっています。
また、CPUだけでなくIOダイも6nmへと微細化され、機能、性能ともに強化。DDR5メモリに対応し12チャネル構成での利用が可能となったほか、2ソケット構成では最大160レーンのPCI Express Gen5が利用可能となっています。
| 第4世代 EPYC 9004 | 第3世代 EPYC 7003 | 第2世代 EPYC 7002 | 第1世代 EPYC 7001 | |
|---|---|---|---|---|
| リリース年 | 2023年/2022年 | 2021年 | 2019年 | 2017年 |
| コードネーム | Bergamo/Genoa/Genoa-X | Milan | Rome | Naples |
| アーキテクチャ | Zen4c/Zen4 | Zen3 | Zen2 | Zen |
| 製造プロセスルール | 5nm | 7nm | 7nm | 14nm |
| 最大CPUコア | 128/96 | 64 | 64 | 32 |
| CPUソケット | SP5 | SP3 | SP3 | SP3 |
| Infinity Fabric | 18GT/秒 | 18GT/秒 | 18GT/秒 | 10.7GT/秒 |
| ソケット数 | 1 / 2 | 1 / 2 | 1 / 2 | 1 / 2 |
| メモリ | DDR5-4800 | DDR4-3200 | DDR4-3200 | DDR4-2666 |
| メモリチャネル | 12 | 8 | 8 | 8 |
| 最大メモリ | 6TB | 4TB | 4TB | 2TB |
| PCI Express | Gen5 160レーン | Gen4 128レーン | Gen4 128レーン | Gen3 128レーン |
AMD EPYC™ 9004 シリーズ・プロセッサー 一覧
| CPU | コア/スレッド | 基本周波数 | 最大周波数 | 最大ソケット数 | メモリ | L3 キャッシュ | TDP |
| EPYC 9754 | 128C/256TH | 2.25GHz | 3.1GHz | 2S | DDR5-4800MHz | 256MB | 360W |
| EPYC 9754S | 128C/128TH | 2.25GHz | 3.1GHz | 2S | DDR5-4800MHz | 256MB | 360W |
| EPYC 9734 | 112C/224TH | 2.2GHz | 3.0GHz | 2S | DDR5-4800MHz | 256MB | 340W |
| EPYC 9684X | 96C/192TH | 2.55GHz | 3.7GHz | 2S | DDR5-4800MHz | 1152MB | 400W |
| EPYC 9384X | 32C/64TH | 3.1GHz | 3.5GHz | 2S | DDR5-4800MHz | 768MB | 320W |
| EPYC 9184X | 16C/32TH | 3.55GHz | 4.2GHz | 2S | DDR5-4800MHz | 768MB | 320W |
| EPYC 9654P | 96C/192TH | 2.4GHz | 3.7GHz | 1S | DDR5-4800MHz | 384MB | 360W |
| EPYC 9654 | 96C/192TH | 2.4GHz | 3.7GHz | 2S | DDR5-4800MHz | 384MB | 360W |
| EPYC 9634 | 84C/168TH | 2.25GHz | 3.7GHz | 2S | DDR5-4800MHz | 384MB | 290W |
| EPYC 9554P | 64C/128TH | 3.1GHz | 3.75GHz | 1S | DDR5-4800MHz | 256MB | 360W |
| EPYC 9554 | 64C/128TH | 3.1GHz | 3.75GHz | 2S | DDR5-4800MHz | 256MB | 360W |
| EPYC 9534 | 64C/128TH | 2.45GHz | 3.7GHz | 2S | DDR5-4800MHz | 256MB | 280W |
| EPYC 9474F | 48C/96TH | 3.6GHz | 4.1GHz | 2S | DDR5-4800MHz | 256MB | 360W |
| EPYC 9454P | 48C/96TH | 2.75GHz | 3.8GHz | 1S | DDR5-4800MHz | 256MB | 290W |
| EPYC 9454 | 48C/96TH | 2.75GHz | 3.8GHz | 2S | DDR5-4800MHz | 256MB | 290W |
| EPYC 9374F | 32C/64TH | 3.85GHz | 4.3GHz | 2S | DDR5-4800MHz | 256MB | 320W |
| EPYC 9354P | 32C/64TH | 3.25GHz | 3.8GHz | 1S | DDR5-4800MHz | 256MB | 280W |
| EPYC 9354 | 32C/64TH | 3.25GHz | 3.8GHz | 2S | DDR5-4800MHz | 256MB | 280W |
| EPYC 9334 | 32C/64TH | 2.7GHz | 3.9GHz | 2S | DDR5-4800MHz | 128MB | 210W |
| EPYC 9274F | 24C/48TH | 4.05GHz | 4.3GHz | 2S | DDR5-4800MHz | 256MB | 320W |
| EPYC 9254 | 24C/48TH | 2.9GHz | 4.15GHz | 2S | DDR5-4800MHz | 128MB | 200W |
| EPYC 9224 | 24C/48TH | 2.5GHz | 3.7GHz | 2S | DDR5-4800MHz | 64MB | 200W |
| EPYC 9174F | 16C/32TH | 4.1GHz | 4.4GHz | 2S | DDR5-4800MHz | 256MB | 320W |
| EPYC 9124 | 16C/32TH | 3.0GHz | 3.7GHz | 2S | DDR5-4800MHz | 64MB | 200W |
関連製品


NVIDIA データセンターGPU Ada Lovelace世代 搭載可能
NVIDIA Ada Lovelace

|

販売終了 |

|
|
|---|---|---|---|
| GPUメモリ | 48GB GDDR6 ECC付き | 48GB GDDR6 ECC付き | 24GB GDDR6 ECC付き |
| メモリー帯域幅 | 864GB/s | 864GB/s | 300GB/s |
| インターコネクト インタフェース | PCIe Gen4x16: 64GB/s 双方向 | PCIe Gen4x16: 64GB/s 双方向 | PCIe Gen4x16: 64GB/s |
| CUDA コア数 | 18,176 | 18,176 | 7,424 |
| NVIDIA 第3世代 RT コア | 142 | 142 | 58 |
| NVIDIA 第4世代 Tensor コア | 568 | 568 | 232 |
| RT コア 性能 TFLOPS | 212 | 209 | – |
| FP32 TFLOPS | 91.6 | 90.5 | 30.3 |
| TF32 Tensor コア TFLOPS | 183 | 366 | 90.5 | 181 | 120 |
| BFLOAT16 Tensor コア TFLOPS | 362.05 | 733 | 181.05 | 362.1 | 242 |
| FP16 Tensor コア | 362.05 | 733 | 181.05 | 362.1 | 242 |
| FP8 Tensor コア | 733 | 1466 | 362 | 724 | 485 |
| ピーク INT8 Tensor TOPS | 733 | 1466 | 362 | 724 | 485 |
| ピーク INT4 Tensor TOPS | 733 | 1466 | 724 | 1448 | – |
| 最大消費電力 | 350W | 300W | 72W |
| フォームファクター | 4.4” (H) x 10.5” (L) 2スロット |
4.4” (H) x 10.5” (L) 2スロット |
ロープロファイル 1スロット |
| 排熱機構 | パッシブ(冷却ファンなし) | パッシブ(冷却ファンなし) | パッシブ(冷却ファンなし) |
| ディスプレイポート | 4 x DisplayPort 1.4a | 4 x DisplayPort 1.4a | N/A |
| マルチインスタンスGPU | N/A | N/A | N/A |
| NVLink | N/A | N/A | N/A |
NVIDIA Ada Lovelace アーキテクチャ
Ada GPU アーキテクチャは、レイ トレーシングと AI ベースのニューラル グラフィックスに革新的な性能を実現できるように設計されています。GPU 性能のベースラインが劇的に上がり、レイ トレーシングとニューラル グラフィックスの転換点となります。
CUDA® コア
Transformer Engine
単精度浮動小数点 (FP32) スループットの高速化と電力効率の向上により、3D モデル開発や CAE シミュレーションなどのワークフローでパフォーマンスが大幅に向上します。混合精度ワークロード向けの拡張 16 ビット数学機能 (BF16) をサポート。
第 3 世代 RT コア
スループットとコンカレント レイ トレーシングとシェーディング機能が強化され、レイ トレーシングのパフォーマンスが向上し、製品の設計/アーキテクチャ、エンジニアリング、建設のワークフローのレンダリングが高速化します。ハードウェアでモーション ブラーを高速化し、驚異的なリアルタイム アニメーションを実現する実物のようなデザインをご覧ください。
第 4 世代 Tensor コア
構造的なスパース性と最適化された TF32 形式のハードウェア サポートにより、すぐにパフォーマンスが向上し、AI とデータ サイエンス のモデル トレーニングが高速化します。DLSS を含む AI により強化されたグラフィックス機能を加速させ、選ばれたアプリケーションで優れたパフォーマンスで高解像度を実現します。
48GB の GPU メモリ
48GB の超高速 GDDR6 メモリで、データ サイエンス、シミュレーション、3D モデリング、レンダリングなどの、メモリ負荷の高いアプリケーションやワークロードに対応します。vGPU ソフトウェアを使用して複数のユーザーにメモリを割り当て、クリエイティブ チーム、データ サイエンス チーム、デザイン チーム間で大規模なワークロードを分散します。
仮想化対応
NVIDIA 仮想 GPU (vGPU) ソフトウェア を活用した次世代の改善により、リモート ユーザーがより大規模かつパワフルな仮想ワークステーションのインスタンスを使用できるようになり、高度なデザイン、AI、計算処理におけるより大規模なワークフローが可能になります。
PCI Express Gen 4
PCI Express Gen 4 対応により、PCIe Gen 3 の 2 倍の帯域幅を提供することで、AI やデータサイエンスなどのデータ集約型タスク向けに CPU メモリからのデータ転送速度が向上します。
データ センターの効率性とセキュリティ
NVIDIA L40 は、24 時間 365 日稼動のエンタープライズ データ センター運用に最適化されており、最大限のパフォーマンス、耐久性、アップタイムを確保するために、NVIDIA によって設計、構築、広範囲にテスト、サポートされています。受動冷却、フルハイト フルレングス (FHFL)、デュアルスロット デザイン、最大 300W のボード電力などの特徴を備え、主要な OEM ベンダーのさまざまな筐体構成に収まります。最新のデータ センター標準を満たし、NEBS レベル 3 に対応し、Root of Trust 技術によるセキュア ブートを備え、データ センターにさらなるセキュリティ層を提供します。
関連製品



NVIDIA RTX™ Ampere世代 搭載可能
NVIDIA RTX™ Ampere

|

販売終了 |

販売終了 |

販売終了 |

販売終了 |

販売終了 |

販売終了 |

|

|
|
|---|---|---|---|---|---|---|---|---|---|
| GPUメモリ | 40GB HBM2 | 48GB GDDR6 | 24GB GDDR6 | 24GB GDDR6 | 20GB GDDR6 | 16GB GDDR6 | 12GB GDDR6 | 8GB GDDR6 | 4GB GDDR6 |
| メモリー帯域幅 | 1,555GB/s | 768GB/s | 768GB/s | 768GB/s | 640GB/s | 448GB/s | 288GB/s | 192GB/s | 96GB/s |
| ECC | Yes | Yes | Yes | Yes | Yes | Yes | Yes | – | – |
| CUDAコア | 6,912 | 10,752 | 10,240 | 8,192 | 7,168 | 6,144 | 3,328 | 2,304 | 768 |
| Tensorコア | 432 | 336 | 320 | 256 | 224 | 192 | 104 | 72 | 24 |
| RTコア | N / A | 84 | 80 | 64 | 56 | 48 | 26 | 18 | 6 |
| 単精度性能(TFLOPS) | 19.5 | 38.7 | 34.1 | 27.8 | 23.7 | 19.2 | 8.0 | 6.7 | 2.7 |
| RTコア性能(TFLOPS) | N / A | 75.6 | 66.6 | 54.2 | 46.2 | 37.4 | 15.6 | 13.2 | 5.4 |
| Tensor性能(TFLOPS) | 623.8 | 309.7 | 272.8 | 222.2 | 189.2 | 153.4 | 63.9 | 53.8 | 21.7 |
| NVLink | Yes | Yes | Yes | Yes | Yes | N / A | N / A | N / A | N / A |
| NVLink帯域幅 | 400GB/s | 112.5GB/s (双方向) |
112.5GB/s (双方向) |
112.5GB/s (双方向) |
112.5GB/s (双方向) |
N / A | N / A | N / A | N / A |
| システムインターフェイス | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x8 | PCIe 4.0 x8 |
| 最大消費電力 | 240W | 300W | 230W | 230W | 200W | 140W | 70W | 50W | 50W |
| 排熱機構 | アクティブ | アクティブ | アクティブ | アクティブ | アクティブ | アクティブ | アクティブ | アクティブ | アクティブ |
| フォームファクター | 4.4″ H x 10.5″ L 2スロット |
4.4″ H x 10.5″ L 2スロット フルハイト |
4.4″ H x 10.5″ L 2スロット フルハイト |
4.4″ H x 10.5″ L 2スロット フルハイト |
4.4″ H x 10.5″ L 2スロット フルハイト |
4.4″ H x 9.5″ L 1スロット |
2.7″ H x 6.6″ L 2スロット |
2.7″ H x 6.4″ L 1スロット |
2.7″ H x 6.4″ L 1スロット |
| 画面出力 | N / A | DisplayPort 1.4a x4 | DisplayPort 1.4a x4 | DisplayPort 1.4a x4 | DisplayPort 1.4a x4 | DisplayPort 1.4a x4 | mDP 1.4a x4 | mDP 1.4a x4 | mDP 1.4a x4 |
| 電源コネクタ | 16ピン PCIe CEM5 x1 | 8ピン CPU x1 | 8ピン PCIe x1 | 8ピン PCIe x1 | 8ピン PCIe x1 | 6ピン PCIe x1 | N / A | N / A | N / A |
NVIDIA RTX テクノロジ
NVIDIA RTX™ テクノロジは、コンピューターグラフィックスにおけるNVIDIAの最も重要な進歩の1つであり、かつてないスピードで実世界をシミュレートする 新世代アプリケーションをもたらします。AI、レイ トレーシング、シミュレーションにおける最新技術が盛り込まれたRTXテクノロジによって驚異的な3Dデザイン、フォトリアルなシミュレーション、圧倒的なビジュアルエフェクトが、かつてないほど高速で実現します。

中心となるテクノロジ
レイ トレーシング
RTXテクノロジはNVIDIA OptiX™、Microsoft DXR、Vulkanといった、最適化されたレイトレーシングAPIにより、映画品質の映像をリアルタイムでレンダリングするという夢を叶えるものです。極めて正確な影、反射、屈折の描写で、フォトリアルなオブジェクトと環境をリアルタイムでレンダリングできるため、アーティストやデザイナーは驚異的な作品をこれまでにない速さで作り出せるようになりました。
人工知能 (AI)
NVIDIA RTXテクノロジはAIのパワーをビジュアル コンピューティングにもたらします。かつてないワークフローの高速化をエンド ユーザーにもたらすAI強化アプリケーションを開発できます。インテリジェントな画像の編集、繰り返しタスクの自動化、コンピューティング負荷の高いプロセスの最適化により、時間とリソースを節約し、アーティストやデザイナーの創作を劇的に加速します。
ラスタライゼーション
RTXテクノロジには、可変レート シェーディング、テクスチャスペース シェーディング、マルチビュー レンダリングなどのプログラミング可能シェーディングにおける最新技術が盛り込まれています。より豊かなビジュアルの制作と大規模なモデルやシーンとのよりスムーズなインタラクティブ性を実現しVR体験が改善されます
シミュレーション
現実感あふれるビジュアルを生み出すには、外観だけでなく、その挙動も重要です。CUDA® コアのパワーと、NVIDIA PhysX®、Flow、FleX、CUDAなどのAPIによりRTXテクノロジではゲーム、仮想環境、特殊効果といったあらゆるケースで、実世界の物体の挙動を正確にモデリングできます。
関連製品

AMD Instinct™ アクセラレーター
AMD Instinct™ MI200 シリーズ・アクセラレーター(CDNA2)は、AMD によるデータセンター向けGPU であり最新の AMD CDNA™ 2 アーキテクチャーをベースにマトリックス・コア・テクノロジーで設計されています。最大規模のエクサスケール・システムを含め、メインストリームのサーバーやスーパーコンピューターにおける発見を加速するように設計されており、HPCや AI などのワークロードを大幅に高速化して、新たな発見を加速します。
また、AMD Infinity Fabric™ テクノロジーは AMD EPYC™ CPUからGPU アクセラレーターへの直接接続を可能にし、統合された最新のサーバー・パフォーマンスを実現することが可能となります。

|
|
|---|---|
| GPU アーキテクチャ | CDNA2 |
| 演算ユニット | 104 |
| ストリーミングプロセッサ | 6,656 |
| 倍精度演算性能(FP64) | 22.6 TFLOPS |
| 単精度演算性能(FP32) | 22.6 TFLOPs |
| 半精度演算性能(FP16) | 181 TFLOPs |
| GPUメモリ | 64 GB HBM2e |
| メモリ帯域幅 | 1638.4 GB/sec |
| ECC | 対応 |
| システム接続 | PCI Express 4.0 x16 |
| フォームファクタ | PCIe Full Height / Length:10.5″ 2スロット |
| 最大消費電力 | 300 W |
| 冷却方式 | パッシブ(冷却ファンなし) |
| プログラミング環境 | ISO C++, OpenCL™, ROCm™ Open Ecosystem Python5 (via Anaconda’s NUMBA) |
関連製品

製品仕様
| CPU |
AMD EPYC 9005 シリーズ・プロセッサー
x 1
AMD EPYC 9005 シリーズ・プロセッサーor AMD EPYC 9004 シリーズ・プロセッサー x 1 AMD EPYC 9004 シリーズ・プロセッサー
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| チップセット | System on Chip ( SoC ) | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| メモリ | DDR5-6000MHz ECC RDIMM / 3DS RDIMM (EPYC 9005) x 12 or DDR5-4800MHz ECC RDIMM / 3DS RDIMM (EPYC 9004) x 12 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ドライブベイ | 3.5/2.5インチ ホットスワップ ( SATA / SAS / NVMe 対応 ) x 12 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| M.2スロット | インターフェイス : PCI-Express 3.0 x2 ( NVMe 対応 ) フォームファクタ : 2280/22110 x 2 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| オプティカルドライブ | USB接続 外付けDVDマルチドライブ オプション | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| グラフィックス | オンボード | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GPU | 2スロット GPU 最大 x 2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ネットワークI/F | 10ギガビット イーサネット ( RJ45 ) x 2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 管理I/F | BMC / IPMI 2.0 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| I/Oポート 背面 | シリアルポート x 1
VGA x 1 USB3.0 x 2 IPMI用 MLAN ( RJ45 ) x 1 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 拡張スロット | PCI Express 5.0 x16 ( FHFL ) x 2
PCI Express 5.0 x16 ( FHHL ) x 2 PCI Express 5.0 x16 AIOM ( OCP3.0 ) x 2 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ケース | 2Uラックマウントケース : W 437mm x H 89mm x D 648mm | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 電源 | 100V 1000W / 200V 1200W リダンダント電源 80-plus Titanium | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OS |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 保守 | 1年間全国出張オンサイトサービス 3年間全国出張オンサイト オプション |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 動作推奨環境 | 温度 : 10 ℃ ~ 35 ℃ (GPU搭載時は25℃) 湿度 : 20 % ~ 80 % (結露なきこと) |
カタログ
商標について
- Intel、インテル、Intel ロゴ、Intel Inside、Intel Inside ロゴ、Intel Atom、Intel Atom Inside、Intel Core、Core Inside、Intel vPro、vPro Inside、Celeron、Celeron Inside、Itanium、Itanium Inside、Pentium、Pentium Inside、Xeon、Xeon Phi、Xeon Inside、Ultrabook は、アメリカ合衆国および/またはその他の国におけるIntel Corporation の商標です。
- AMD、AMD EPYC™、AMD Ryzen™ 、AMD Radeon™ 、Radeon Instinct™ は、アメリカ合衆国および/またはその他の国におけるAdvanced Micro Devices,Incの商標です。
- NVIDIA、NVIDIA のロゴ、GeForce、 CUDA、 NVLINK、SLI、Tesla、Quadro、および SHIELD は、米国またはその他の国における NVIDIA Corporation の商標または登録商標です
- Supermicroは商標であり、米国のSuper Micro Computer, Inc.およびその他の国における子会社の登録商標です。
- Red Hat、Red Hat Enterprise Linux、Shadowmanロゴ、JBossは米国およびその他の国において登録されたRed Hat, Inc.の商標です。
- Linux(R)は米国およびその他の国におけるLinus Torvaldsの登録商標です。
- SUSEおよびSUSEロゴは、米国およびその他の国におけるSUSE LLCの登録商標です。
- VMwareおよびVMwareの製品名は、VMware, Inc.の米国および各国での商標または登録商標です。
- Microsoft、Windows、MS-DOS、Windows NT、Windows Vista、Windows Server、Windows Azure、SQL Serverおよび Microsoft Exchange Serverまたはその他のマイクロソフト製品の名称および製品名は、米国 Microsoft Corporation の、米国およびその他の国における商標または登録商標です。
- UNIXは、米国およびその他の国におけるオープン・グループの登録商標です。
- その他弊社ウェブサイト(本サイト)に表示・記載されている会社名、製品名およびロゴ等は、各社の登録商標または商標です。
